The first plenary was delivered by Christine Borgman (UCLA) talking us through the issues around research data management.
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-plenary-1-borgman
She laid out some cautionary thoughts - librarians thinking they can handle 'data' the way we handle other information bundles is naive in the extreme. She was complimentary of Australia's 'broad' approach to research data management, but a black box approach to data obscures the complexity of what we are dealing with.
 |
| A preview of Borgman's upcoming book 'Big Data, Little Data, No Data |
|
|
|
No-one can actually define data and even examining specific cases multitudes of complexity occur:
Different fields have different technologies, behaviours, and structures for dealing with, presenting and interpreting data. Different geolocations within a field will have significant variances.
Some of the issues to be dealt with revolve around the personal. Researchers often feel the data they have is their 'dowry' and makes them valuable to their institutions and sharing diminishes its value. Others don't mind sharing but they want personal contact with the person they are sharing for a number of reasons, and feel uncomfortable with unmediated access. On the receiving end researchers don't necessarily like using someone else's data because of issues of trust.
When you start examining the data, or as I coined it 'metareality', even more issues of complexity arise. One neat example was the fact that there are several taxonomies for describing drosophila genomes - how open is the data if it's coded in a way the user doesn't use?
And what about access? At what level of granularity do you provide access? A single link to a zip file of everything? URIs for individual files, or as Borgman mentioned 'A DOI for every cell in a spreadsheet'? What about format? What role do we have in ensuring the format is accessible over time?
What are the effects of knowledge infrastructures (institutional, national, discipline) on authority, influence and power? Recommended reading:
http://knowledgeinfrastructures.org/
A strong case was made for skill sets not normally associated with librarians - economics, records management (determining at time of storage how long you're going to store it) and archival practice (provenance is a huge factor in building trust). It's long been said that some areas of JCU assume the Library will take on maintenance of research data management - we really need to be aware of just what is involved and how much we will need to be embedded in research areas as partners and the resources and skills that will demand. In an aside Christine mentioned a 200 page book telling you how simple data citation is!
Hacking the library catalogue: a voyage of discovery
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-session-2-kreunen
A kind of interesting talk from UniMelb's University Digitisation Centre (UDC) about the work it's 5.4 staff do particularly in trying to manage metadata for scans from the print collections and how they managed to scrape data from the catalogue as automatically as they could. I could relate to the speedbumps they kept hitting with things that should work but don't, for example they figure out how to get their catalogue to present a record in XML, but the scanning software wouldn't accept the XML as valid, but the vendor insisted it was, so workaround on workaround.
Marking up NSW: Wikipedia, newspapers and the State Library
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-session-2-cootes
A cool project involving the NSW State Library and some interested public libraries that identified 20 volunteers to enrich wikipedia entries for local newspapers that had been digitised and added to Trove. Lots of liaison with Wikipedia because that community is very sensitive lots of changes in a narrow section. So the word was sent out that the volunteers would be doing work and that other contributors should be 'nice' while they found their feet. One interesting observation was that it was 'unlibrarianlike' to have to accept that once you've added content in wikipedia it is no longer 'yours' and you have no veto over how it's changed, any more than any of the thousands of people who actively contribute to wikipedia.
I think we should consider this as another step in processing records for NQHeritage. I think as a profession we should be augmenting and improving wikipedia with reputable resources. As was pointed out: Wikipedia is the 5th most popular site on the web - users are going to use it so lets make it better - and expose our resources through this incredibly popular portal.
Journey into the user experience: creating a library website that's not for librarians
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-session-4-murdoch
I did a standing ovation at the end of this one. Loved that they went all Steve Krug on usability testing. Loved the heat map (I will have find a way of creating one for our site through the Google Analytics data). Which effectively showed that 3 links were pretty much covering 90+% usage.
Jealous that their university web/marketing section trusted them enough to build templates outside the corporate templates (in fact the library laid the path for the rest of the university.
Check out what they ended up with!
http://www.library.aut.ac.nz/
Influences of technology on collaboration between academics and librarians
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-session-5-pham
Report about an indepth case study of acadamic/librarian relations revolving around information literacy training and the learning management system at Monash. Pleased to say we have moved beyond some of the problems identified (like lecturers not seeing why a librarian doing IL for their students would need access to the subject in Blackboard) but I think our advances are patchy.
Just accept it! Increasing researcher input into the business of research outputs
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-session-5-ogle
A report on the University of Newcastles improvements to automating the HERDC reporting and again it was nice to see we were more advanced in this area - their next big project was to integrate their research database with their institutional repository, something our Library, Research Services and ITR sorted a couple of years ago. I wonder what they would have thought of David Beitey's work on the Research Portfolios.
The day was rounded off by a roller coaster presentation 'Social media as an agent of socio-economic change: analytics and applications' by Johan Bollen from Indiana U
Persistent URL:
http://www.vala.org.au/vala2014-proceedings/vala2014-plenary-2-bollen
Johan is probably best known for work showing a correlation between twitter 'mood' and stock market movements. Which came out of a project that assigned 'emotion' to tweets through 'big data' analysis applying
Affective Norms for English Words (ANEW) which:
"...provides a set of normative emotional ratings for a large number
of words in the English language. This set of verbal materials have been
rated in terms of pleasure, arousal, and dominance in order to create a
standard for use in studies of emotion and attention."
Turns out that 3 days after a spike in negative feeling in the twittersphere the Dow Jones will drop, and a positive spike will correlate with an increase after the same lag.
Bollen was engaging champion for the wisdom of crowds, pulling anecdotes and finding from all over the place to make his convincing case.
1 in 3 people in the world has internet access - North America topping the list with nearly 80% penetration and Africa at the bottom with it below 20% massive recent growth in Asia and the middle East.
If Twitter 'nation' was a nation only China and India would have more people, and analysing linkages and traffic can tell you much about the macro movements resulting from the micro actions of individuals.
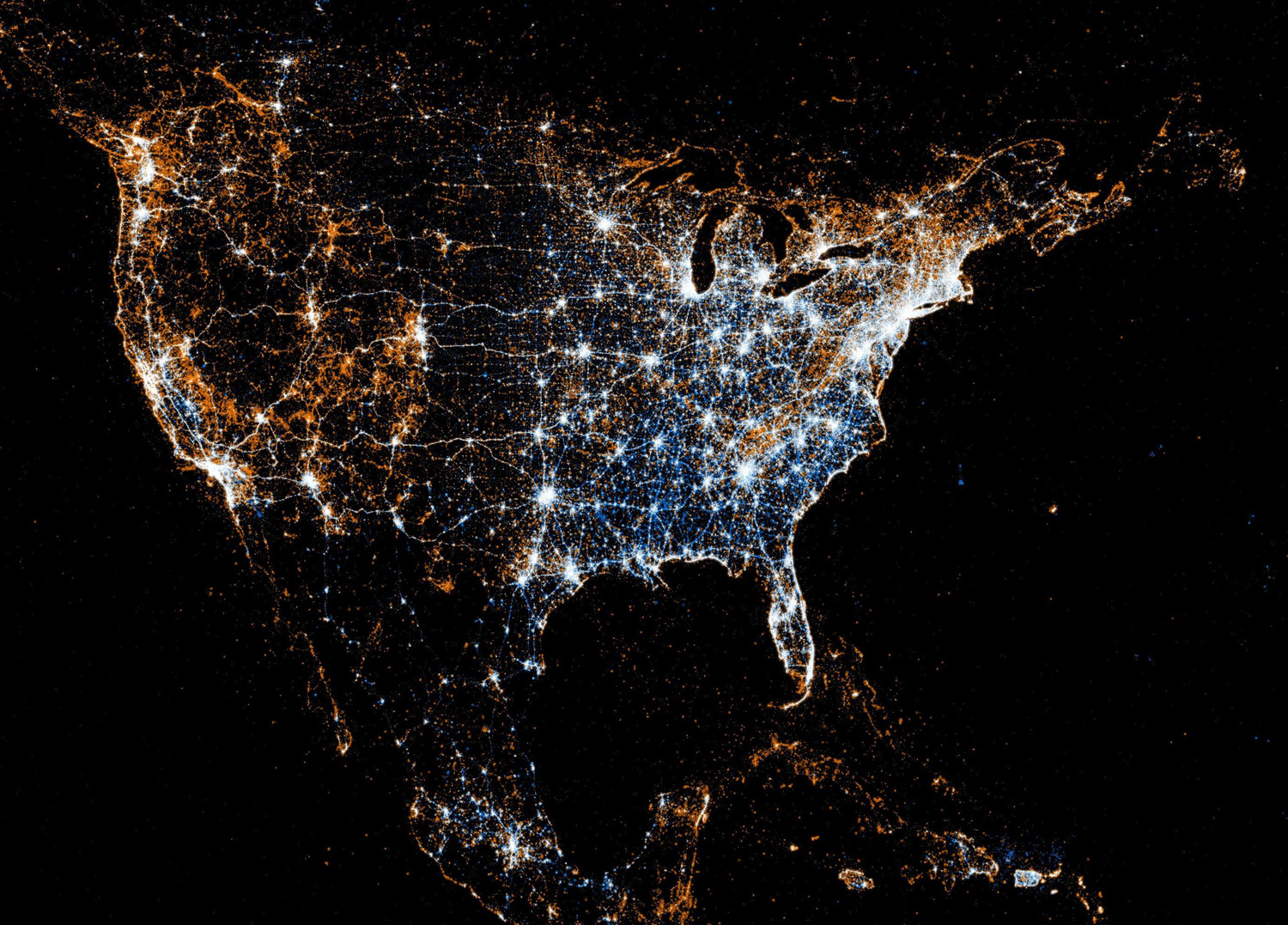 |
| Flickr (orange) and Twitter (blue) map created by Eric Fischer |
While some think that the internet, by giving everyone a voice, will turn society into an 'idiocracy' Johan does not share this pessimism and gave a couple of examples where crowds do actually make better decisions than experts, and in fact showed us a mathematical formula (
Condorcet's jury theorem) that shows a jury made up of people who are right even slightly more than 50% of the time gets more and more accurate the higher the number of jurors. Then pondered whether the current American political situation was because too many people are right just under 50% of the time which by the same formula magnifies the wrongness of the crowd.
Johan had 80 slides both whimsical and insightful, hope the video is up soon.
The finale was his mojito-fueled solution for research funding that eliminated the tortuous and wasteful process of writing and reviewing of proposals. Basically allocate an equal share of the total amount available to all the researchers but require the researchers to give half to a researcher whose work they think is valuable, a bunch of checks would need to be in place, but you would be crowdsourcing research funding allocation to the researchers themselves. The modelling shows that that any 'waste' would be less than the amount of resources spent in maintaining the current proposal/review system. Personally I worried that a standout researcher would receive way more money than required, but I wasn't Mojito assisted. Johan's explanation was much more cogent than mine.
Some links and thoughts to ponder:
- Digital Humanities experiment with big data http://www.themacroscope.org/
- Mood analysis shows that negative tweeps tend to cluster in networks with each other
- In networking terms a retweet is as valuable as the original tweet
- Bollen mistrusts Altmetrics because the major drivers are media outlets, not individuals
For another view of all the bits I missed or mucked up try
Deborah Fitchett's or
Hugh Rundle's blogs.