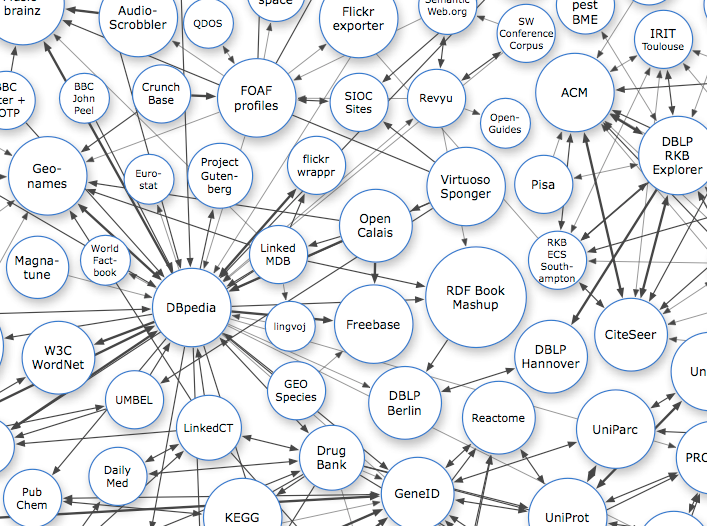
It was great to see under the hood and spakfil my limited understanding of what it all meant. I liked that Tim and Paul be aware of 'Linked Open Data (LOD) Paralysis' (see image below) and keep dragging us back to practical uses.
So I now know RDFa is the defacto standard, that Google, Microsoft Bing and Yahoo actually cooperated. Handcrafting your own linked data in html code gave us an object lesson in why you wouldn't only create this sort of markup using computers. But as the 'other' Tim and Paul point out - libraries already have this information stored in databases in a highly structured format, it just that once we publish it to the web we throw the structure out so it looks nice on a page. Generating this same content with embedded Linked Open Data (LOD) from these databases shouldn't be hard.
LOD maintains the structure of the data (so it makes sense to computers) without changing how it looks (which makes sense to humans).
'But why would we care what those dumb old computers think? ' I hear you ask. Because once computers understand that a particular text string is a person, building, organisation or tea cozy, with a bunch of attributes, that may also be shared with other 'things' we make clearly visible connections that are invisible or buried to us with unstructured information.
It's early days but as LOD becomes the default the possibilities expand. If you want to see an example of it search google - the panel on the right hand side is pulling that information from various sites using LOD.
The other take out was search engines prefer LOD enriched sites, paying attention to content that was just a long string of characters to be ignored by Google (with 'normal' pages Google mostly relies on HTML title tag. LOD enhanced content opens up discovery.
Using the resource tag is like a web-based authority list. If you link a data element to verified source your item is automatically linked to every other data element anyone else has linked to that same resource. Which in turn expands the number of 'attributes' that item has. Bear with me with this tortuous example. But say you link a publication's author to a verified linked data target. And say someone else links a player in a list of former Seattle Seahawks greats to that same person. Then without any human intervention a third party locating the book can see that the author once played in the Superb Owl (HT @StephenAtHome)
Paul and Tim list a bucket load of resources here: http://t.co/RiIlQk4s8J

dbpedia is the semantic web mirror of wikipedia and common datastore the resource tag is pointed at. It might help to get a sense of just how much information is available about a 'thing' but just taking a look at the entry for J.K Rowling (courtesy of the Fantales exercise) scroll down to see the extent of informational attributes recorded for the author.
What does it mean for us? Well the biggest buckets of structured data we control directly are our catalogue and eprints - neither of the frontends we provide for them (Tropicat & ResearchOnline@JCU) currently have any facility for integrating LOD - but perhaps we can encourage developments in that area from the vendors, likewise Summon might be pushed in that direction, and Tim and Paul were clear that Trove was moving toward increasing LOD - initially driven because 76% of Trove referrals come from Google, and LOD promotes your resources in Google. Trove harvests our eprints through OAI-PMH (which is highly structured XML) so we benefit from their work. Also on my wish list is LOD capability in any new CMS JCU acquires.
No comments:
Post a Comment